21년 3월 23일
코드스테이츠 부트캠프 21일차
Week3 Linear Algebra (선형대수)
오늘의 나를 뒤돌아보며,
캐글에 있는 데이터를 불러와서 기존의 label과, clustering 이후의 label을 비교하는 과정에서 문제가 생겼었다. 비교를 하기 위한 2개의 label을 만들었고 그 label을 데이터프레임으로 만들어 보기도 하고, 시리즈로 만들어 보며 합치려고 노력하였다. 그런데 합쳐도 NaN값이 나오고 오류가 발생하여 조금씩 수정하면서 2시간 가량 문제를 해결하지 못했다. 문제점은 데이터를 불러오는 read_csv부터 잘못된 것이였다. 다행히 문제점을 찾아서 과제제출을 했다.... 휴
오늘 첫 단추부터 잘못 끼워서 고생했는 부분! 꼭 이런 실수 하지말자.
데이터를 불러오는 read_csv 코드를 입력할 때 index_col = [0]를 입력하였다.
이는 첫 번째 컬럼을 인덱스로 지정하는 것을 의미한다.
|
1
2
3
4
|
df = pd.read_csv(io.BytesIO(myfile['data.csv']), index_col = [0], encoding = 'cp949')
# 이렇게 하면 안됨!!! index_col = [0]를 하게되면 첫 번째 컬럼을 인덱스로 지정하는 것이다.
인덱스란 행을 의미하는 것이다.
|
cs |
id 값이 인덱스로 지정되면서 id 값에 있는 value들을 사용해야하는데 움직이지도 못하는 발목이 묶인상태가 되어서 그 후에 과제를 하며 실행하는데 문제가 발생하는 것이였다.
|
1
|
df = pd.read_csv(io.BytesIO(myfile['data.csv']), encoding = 'cp949')
# index_col = [0]를 넣으면 안됨! |
cs |
ㅇㅁㄻㄴㅇ첫 번째 컬럼을 인덱스로 지정하는 경우가 언제인지 알아보고 다시 정리하자
21일차
Clustering
키워드
- Scree Plot
- Supervised / Unsupervised Learning
- K-means clustering
Machine Learning
머신러닝은 지도 학습 (Supervised Learning)과 비지도 학습 (Unsupervised Learning)으로 나뉜다.
지도학습은 트레이닝 데이터에 label이 있을 때 사용할 수 있다.
-분류 (Classification) : 주어진 데이터의 카테고리 혹은 클래스 예측을 위해 사용됩니다. 미리 레이블이 붙어 있는 데이터들을 학습해서 그걸 바탕으로 새로운 데이터에 대해 분류를 수행한다.
-회귀 (Prediction) : continuous 한 데이터를 바탕으로 결과를 예측 하기 위해 사용됩니다.
비지도학습은
-클러스터링 (Clustering) : 데이터의 연관된 feature를 바탕으로 유사한 그룹을 생성하는 것이다. 레이블을 모르더라도 그냥 비슷한 속성을 가진 데이터들끼리 묶어주는 역할을 한다.
-차원 축소 (Dimensionality Reduction
-연관 규칙 학습 (Association Rule Learning)
(아래의 표가 뜻하는 바는 아직 모르겠지만 차츰 배워가면서 어떤 것을 의미하는지 알게 될 것이라 생각한다.)
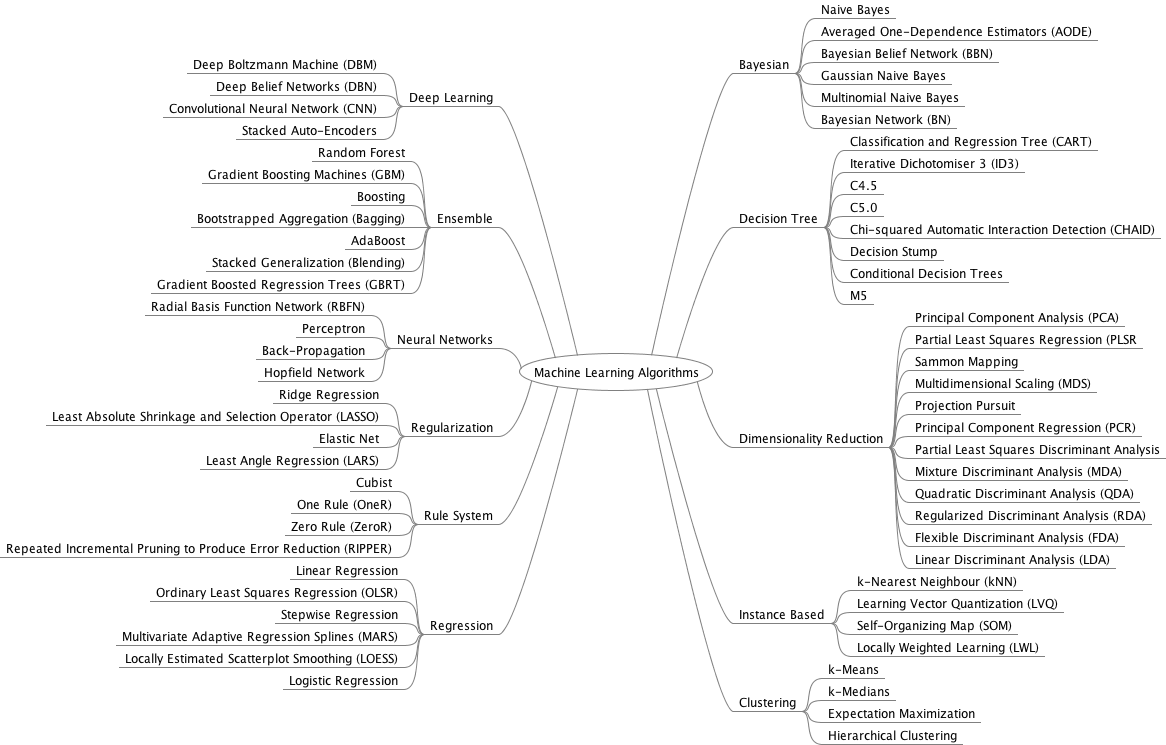
Clustering (군집화)
Clustering은 Unsupervised Learning Algorithm의 한 종류로 주어진 데이터들이 얼마나, 어떻게 유사한지 파악할 수 있다. 그래서 주어진 데이터셋을 요약 및 정리하는데 매우 효율적인 방법들 중 하나로 사용됨
clustering의 목표는 서로 유사한 데이터들은 같은 그룹으로, 서로 유사하지 않은 데이터는 다른 그룹으로 분리하는 것이다. 그렇다면 다음과 같은 2가지 사항을 고려해야한다.
- 몇개의 그룹으로 묶을 것인가
- 데이터의 “유사도”를 어떻게 정의할 것인가 (유사한 데이터란 무엇인가)
이 2가지 사항을 해결할 수 있는 방법이 k_means 알고리즘이다.
k는 데이터 셋에서 예상되는 cluster(그룹)의 수이다.
means는 각 데이터로부터 데이터가 속한 cluster의 중심까지의 평균거리를 의미하는데 이 값이 최소화되는 게 좋다.
K-means Clustering
과정
- K개의 임의의 중심점(centroid)을 설정한다.
- 각 데이터들을 가장 가까운 중심점으로 할당한다.
- 군집으로 지정된 데이터들을 기반으로 해당 군집의 중심점을 업데이트한다.
- 2~3번 단계를 그래서 수렴이 될 때까지 반복한다.
|
1
2
3
4
5
6
|
# kmeans 클러스터링
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters= 2, random_state=42)
kmeans.fit(scal_df)
labels = kmeans.labels_
|
cs |
Scree plot
몇 번째의 주성분까지 추출해야 이 데이터를 적절한지 판단하기 위해 보통 Scree Plot을 사용한다.

y축은 Eigenvalue 값이다.
그래프를 보면 꺽이는 지점 전까지가 주성분이 데이터에서 차지하는 비중이 크다는 것을 알 수 있다. 그래서 꺽이는 지점까지 주성분으로 추출하기 적절한 데이터라고 본다.
#Elbow Method : 팔꿈치마냥 갑자기 꺽이는 지점이 있는 부분을 선택하는게 적절하다.
Feature scaling
서로 다른 변수의 값에 대한 범위를 일정한 수준으로 맞추는 작업.
표준화(Standardization)와 정규화(Normalization)가 있다.
표준화: 데이터의 피처들 각가의 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환해주는 것
정규화: 서로 다른 피처들의 크기를 통일하기 위해 크기를 변화해주는 것입니다.
StandardScaler : 피처들을 평균이 0이고 분산이 1인 값으로 변환을 시켜준다.
|
1
2
3
4
5
|
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
scaler.fit(x_df)
x_scaled=scaler.transform(x_df)
|
cs |
참고하면 좋은 블로그. (배울게 많은 블로그다)
공부합시다
Data analyst 📊
jaaamj.tistory.com
'개발 관련자료 > ML, DL' 카테고리의 다른 글
| Multiple Regression (0) | 2021.04.22 |
|---|---|
| Simple Regression (0) | 2021.04.22 |
| Dimension Reduction (차원축소) #아직 이해를 못해서 개념 정리 다시 해야함 (0) | 2021.04.21 |
| 선형대수(Linear Algebra) (0) | 2021.04.01 |
| Vector / Matrix (0) | 2021.04.01 |