21년 3월 19일
코드스테이츠 부트캠프 16일차
Week3 Linear Algebra
오늘의 나를 뒤돌아보며,
선형대수를 공부하며 고등학교 수학 공부할 때 봤던 벡터가 오랜만에 봐서 알거같은데 낯설기도해서 알쏭달쏭한 상태이다. 오늘 배웠다고 바로 개념을 이해하고 내 것으로 만들 수는 있지만 아직 나는 그렇지 않다. 정리를 잘하고 복습을 하면 내 것으로 만들 수 있다.
오랜만에 봐서 어려움을 느끼지만 나중에는 별거없다고 생각할꺼야!
파이썬 for 문과 같은 문법 공부를 다시 정리해야겠다. 아직 파이썬의 개념을 제대로 공부했는게 아니라서 서툴다.\
나도 드디어 블로그에 코드를 원하는 방식으로 복사하는 방법을 알게되었다. 오예~~~~ :)
16일차 Linear Algebra +
선형대수
키워드
- 벡터와 매트릭스의 기본 연산
- 상관계수
- 공분산
- Linear Projection
어떤 데이터의 관계를 알기 위해서 평균과 분산을 이용한다. 평균인 기대값을 구하기 위해 이용하고, 분산은 데이터가 얼마나 퍼져있는지 알기 위해 이용한다.
Mean (평균)
말 그대로 평균!
Variance (분산)
|
1
|
data.var(ddof=0)
|
cs |
여기서 ddof를 0으로 지정해 주는 것은, 모집단의 분산을 계산하기 위함이다. ddof를 설정하지 않을 경우, default 값인 1로 설정되어 '샘플의 분산'으로 계산이 된다.
★분산을 왜 사용할까?
분산은 데이터가 얼마나 퍼져있는지를 측정하기 위해 사용한다.
각 값들의 평균으로부터 차이의 제곱 평균으로 분산을 구하기 위해서는 평균을 먼저 구해야 한다.
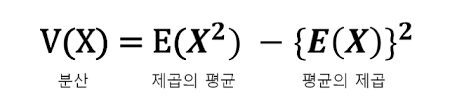
분산의 계산식에 제곱이 들어가 데이터의 스케일에 영향을 받는데
표준편차는 루트를 써서 보정이 된다.
선형대수인데 분산을 왜 쓰냐...?
(이것에 대해서 알아보고 작성하자)

Standard Deviation (표준편차)
std(v)로 코드 작성
분산 값에 √()를 씌운 것이다.

Covariance (공분산)
X와 Y라는 변수가 있다고 가정하면, cov(X,Y)<0 이면 음의 상관관계를 갖게된다. cov(X,Y)>0 이면 양의 상관관계를 갖게된다. cov(X,Y)=0 이라는 것은 상관관계가 0이라는 것이다.
★공분산을 왜 사용할까?
1개의 변수 값이 변화할 때 다른 변수가 어떠한 연관성을 나타내며 변하는지를 측정하기 위함이다.
공분사을 구하는 함수는 cov(x,y)이다.

분산에서 스케일을 조정하기 위해 표준편차를 사용했던 것처럼, 공분산도 크기에 영향을 받는데 이때 상관계수로 조정할 수 있다.
Correlation coefficient (상관계수)
공분산을 두 변수의 표준편차로 각각 나눠주면 스케일을 조정할 수 있으며 상관계수라고 부른다.
상관계수를 구하는 함수는 corrcoef(x,y)이다.
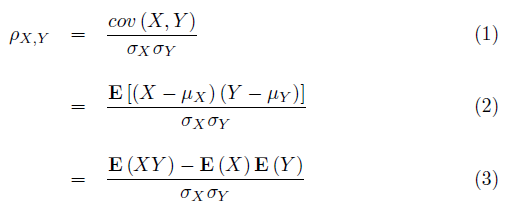
상관계수를 구하는 공식은 공분산에서 X와 Y 편차의 곱을 나눠주면 된다.
상관계수의 값은 -1 ~ 1의 값을 가진다.
상관계수는 Pearson correlation 이라 부르며 이는 데이터로부터 분산과 같은 통계치를 계산 할 수 있을 때 사용가능하다.
Spearman correlation
|
1
|
scipy.stats.pearsonr( )
|
cs |
numeric 데이터가 아닌 categorical 데이터의 통계치를 구하기 위해 사용한다.
Span
Span 이란, 주어진 두 벡터의 (합이나 차와 같은) 조합으로 만들 수 있는 모든 가능한 벡터의 집합이다.
span이 1 이라는 것은 같은 선상에 있는 선형 관계(linearly dependent)에 있다고 할 수 있다.
Basis
공간(span)을 만들어 낼 수 있는 선형관계가 아닌 벡터들의 모음
Rank
매트릭스의 rank란, 매트릭스의 열을 이루고 있는 벡터들로 만들 수 있는 (span) 공간의 차원이다.
matrix의 차원이 rank 보다 클 경우, matrix의 행 또는 열을 구성하는 벡터들 중, 선형관계의 벡터가 있다고 볼 수 있다.
다른 말로, rank는 matrix의 행 또는 열을 구성하는 벡터들 중, 서로 linearly dependent인 벡터의 개수이다.
(행렬의 열과 행의 rank는 같은 값을 가진다!)
Rank를 확인 하는 방법은 여러가지 가 있지만, 그 중 Gaussian Elimination 가 있다.
행렬로 인한 결과로 차원이 선이되면 Rank = 1, 면이 되면 Rank = 2가 된다.
rank가 3이라는 것은 세 개의 벡터로 3차원 span을 채울 수 있다는 것이다. (과제에서 다룬 내용)
꼭 기억하고 넘어가야 하는 것
★ 표준편차를 구하는 순서
평균 → 편차 → 분산 →표준편차

★루트(제곱근)을 표현하는 2가지 방식
|
1
2
3
4
5
6
7
8
9
10
|
import math # 수학 모듈 호출
# 루트(제곱근)을 표현하는 2가지 방식
math.sqrt(x) # x의 루트
x**(1/2)) # x의 루트
print "math.sqrt(100) : ", math.sqrt(100) # 100의 제곱근 = 루트 100 출력하기
결과 값
math.sqrt(100) : 10.0
|
cs |
★공분산과 상관계수 구하는 함수
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import numpy as np
x = [1, 3, 5, 7, 9]
y = [1, 5, 7, 9, 11]
np.cov(x,y)[0,1] # 공분산 구하는 함수
np.corrcoef(x,y)[0, 1] # 상관계수 구하는 함수
np.cov(x, y) #사용하면 x의 분산, y의 분산과 함께 x와 y의 공분산을 계산
np.cov(x, y)[0, 1] #공분산만 보고자 한다면\
출력값:
array([[10. , 12. ],
[12. , 14.8]])
12.0
|
'개발 관련자료 > ML, DL' 카테고리의 다른 글
| Multiple Regression (0) | 2021.04.22 |
|---|---|
| Simple Regression (0) | 2021.04.22 |
| Clustering (0) | 2021.04.21 |
| Dimension Reduction (차원축소) #아직 이해를 못해서 개념 정리 다시 해야함 (0) | 2021.04.21 |
| Vector / Matrix (0) | 2021.04.01 |