bias와 variance는 모델의 loss 또는 error를 의미한다.

붉은색 영역은 Target 값(참 값)을 의미하고 / 푸른색 영역은 추정 값을 의미한다.
Bias는 참 target 값과 추정 값들의 차이(평균간의 거리)를 의미하고, Variance는 추정 값들의 흩어진 정도를 의미한다.

당장 떠오르는 예로는, 군대에서 20발 사격을 할 때 표적지의 정중앙을 맞추려고 노력한다. target인 정중앙에서 얼마나 떨어진 지점에 쐈는지의 차이가 bias이고, 20발을 쐈을 때 탄착군이 형성되는데 이를 variance라고 이해하자!
위 그림을 보면 물론 target인 정중앙을 맞추지 못해서 bias는 크지만 variance는 낮다는 것을 알 수 있다. 저렇게 쏘면 진짜 잘쏜거지 ㅎㅎ
다시 그림 1을 보면 (a)는 모델이 가장 좋다는 것을 알 수 있다.
(b)는 bias는 작은데, variance가 큰 모델이다.
(c)는 bias는 큰데, variance가 작은 모델이다.
(d)는 bias와 variance가 모두 큰 모델이다.
b,c,d 모두 error가 있는데 발생하게 된 원인이 다른 서로 다른 유형의 error이다.
-variance가 큰 (b)모델은 train data에 over-fitting된 것이 원인이고, 이는 너무 train data에 fitting된 모델을 만들어서 test data에서 오차가 발생한 것을 의미합니다.
-bias가 큰 (c) 모델은 test data를 위한 학습이 덜 된 것이 원인이고, 이는 train data와 test data간의 차이가 너무 커서 train data로만 학습한 모델은 test data를 맞출수가 없는 것입니다. 만일, (c) 그림이 train data에 대한 것이라면 train data에 대해 under-fitting 즉, 학습이 덜 된 모델이라고 할 수 있습니다.
-(d)는 둘 다의 경우로 생각할 수 있겠습니다.
Bias-Variance Trade Off
train data에 너무 잘 맞게 학습시키는 것은 모델 복잡도를 높이는 것을 의미한다.
그렇다면 모델 복잡도를 높이면 over-fit 이 되는 이유는 뭘까?
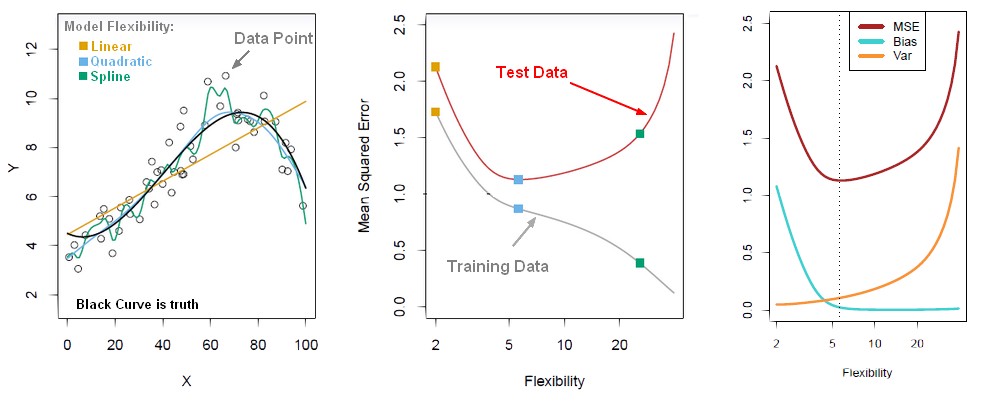
최적의 모델 복잡도는 위 그림의 세번 째처럼 bias와 variance가 교차하는 부분에서 MSE or total test loss(bias와 variance의 합)가 가장 작은 점의 복잡도를 갖는 것이다. 즉, 모델의 학습이 train error의 최소가 아닌 test error가 최소가 되도록 해야 한다는 것으로 이해할 수 있다.
추가적으로 고려해볼 방법은 처음부터 train set이 갖는 변동을 작게 만드는 것이다. 이 방법이 바로 n-fold cross validation으로 여러 data set을 만들어 평균적으로 적용시킴으로써 sub set간의 변동을 줄이는 방법이라고 할 수 있다.

variance는 추정 값의 평균과 추정 값들간의 차이에 대한 것이고, bias는 추정값의 평균과 참 값들간의 차이에 대한 것
그런데 모델 학습을 하면 왜 MSE는 작아지고 ‘0’에 가까이 갈까?
위의 MSE의 수식을 보면 bias와 variance가 모두 제곱 텀이므로 둘 다 양수 입니다. 즉 MSE가 고정되면 하나가 커지면 하나는 작아지는 trade off 관계에 있습니다. 그런데 왜 학습을 하면 ‘0’에 가까이 수렴할까요?
우리는 학습할 때 bias나 variance의 어느 한쪽을 보고 학습하는 것이 아니라 이 둘을 더한 MSE가 작아지도록 학습을 하기 때문에 최적 값을 알아서 찾아 학습을 하게 됩니다.
b-v trade off를 한번 더 반복해 보면, 모델 복잡도를 높이면 train data에 대한 bias와 variance는 계속해서 모두 감소합니다(bias+variance이 작아지도록 학습시키므로). 그런데 test data로 평가를 해보면 MSE loss가 어느시점부터 커지는데, 커지는 이유는 test data의 MSE loss 중에서 variance가 다시 커지기 때문이라고 이해하면 좋을 것 같습니다.
딥러닝에서도 이러한 문제를 없애기 위한 다양한 trick(regularization, dropout, domain adaptation 등)이 존재한다.
참고
https://modulabs-biomedical.github.io/Bias_vs_Variance
https://en.wikipedia.org/wiki/Mean_squared_error
'개발 관련자료 > ML, DL' 카테고리의 다른 글
| 역전파(Backpropagation) 알고리즘 (0) | 2021.06.16 |
|---|---|
| 퍼셉트론(Perceptron) (0) | 2021.06.16 |
| L1 regularization, L2 regularization 간단한 개념 (0) | 2021.06.11 |
| Ridge regression과 Lasso regression 개념 (0) | 2021.06.11 |
| cross validation(교차검증) (0) | 2021.05.05 |